C言語 ポインタ確認テスト
以下の問題を解いて、理解度を確認しましょう。
ポインタの基本
次のような実行結果が得られるように、プログラム中の空欄に入るものを選択しなさい。
value = 7 ← ここは、必ず 7
#include <stdio.h>
int main(void)
{
int n = 7;
int *p;
p = ;
printf("address = %d\n", &n);
printf("value = %d\n", );
return 0;
}配列とポインタ
次の実行結果をみて、下の問に答えなさい。
n[1] = 3
n[2] = 5
n[3] = 7
n[4] = 11
#include <stdio.h>
int main(void)
{
int i;
int n[] = {2, 3, 5, 7, 11};
int *p;
p = [a];
for (i=0; i<5; i++) {
printf("n[%d] = %d\n", i, *p);
p++;
}
return 0;
}プログラム中の空欄 [a] に、&n[0] が入っているとする。
このとき、空欄 [a] に「 」を入れても、上と同じ実行結果が得られる。
構造体とループ
次のような実行結果が得られるように、プログラム中の空欄に入るものを選択しなさい。
国語 = 68
#include <stdio.h>
struct Score {
int kokugo;
int math;
int eigo;
};
int main(void) {
struct Score st[] = {{58, 74, 69}, {68, 78, 88}};
int i;
for (i=0; i<2; i++) {
printf("国語 = %d\n", st[i]kokugo);
}
return 0;
}論理演算
次のプログラム1と同じ結果が得られるように、下のプログラム2の空欄 [a] に入るものを選択しなさい。
[プログラム1]
if (a > 0 && a < 10) {
printf("OK");
}
[プログラム2]
if ( ) {
printf("OK");
}多重ループ
次のプログラムの実行結果について、空欄に入る数値を入力しなさい。
int i, j;
for (i = 1; i <= 2; i++) {
for (j = 3; j <= 4; j++) {
printf("i=%d j=%d\n", i, j);
}
}i= j=
i= j=
i= j=
最小値を求めるアルゴリズム
次の最小値を求めるプログラムをみて、下の問に答えなさい。
int a, b, c;
int min;
a = 3; b = 1; c = 2;
min = a;
printf("min=%d\n", min);
if (b [a] min) min = b;
printf("min=%d\n", min);
if (c [a] min) min = c;
printf("min=%d\n", min);(1) プログラム中の空欄 [a] に入る記号(2つとも同じ記号が入る)を選択しなさい。
答え:
(2) 上のプログラムの実行結果を下に示している。空欄に入る数値を入力しなさい。
min=
min=
制御構造
次のア~エのプログラムの制御構造について、最も適切なものを選択しなさい。
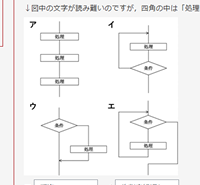
ア:
イ:
ウ:
エ:
制御構造の記述
プログラムの制御構造に関する記述のうち、適切なものはどれか。
ポインタと関数
次の(C言語の)プログラムを見て、下の問に答えなさい。
void func(int *b)
{
*b = 5;
}
int main(void)
{
int a;
a = 3;
printf("a = %d\n", a);
func(&a);
printf("a = %d\n", a);
}この実行結果の空欄に入る数値(半角)を入力しなさい。
a=
配列とポインタ(関数渡し)
次の(C言語の)プログラムを見て、下の問に答えなさい。
void g(int c[])
{
int w;
w = c[0];
c[0] = c[1];
c[1] = w;
}
int main(void)
{
int i;
int n;
int a[] = { 5, 6, 7 };
n = sizeof(a) / sizeof(a[0]);
for (i = 0; i < n; i++) {
printf("a[%d]=%d\n", i, a[i]);
}
g(a);
printf("\n");
for (i = 0; i < n; i++) {
printf("a[%d]=%d\n", i, a[i]);
}
}この実行結果の空欄に入る数値(半角)を入力しなさい。
a[1]=
a[2]=
a[0]=
a[1]=
a[2]=
探索の用語
次の文章の空欄に入る最も適切なものを選択しなさい。
探索において,着目する項目(例えば探したい値)のことを という。
探索手法の分類
次の文章の空欄に入る最も適切なものを選択しなさい。
: ランダムに並んだデータの集まりからの探索を行う。
: 一定の規則で並んだデータの集まりからの高速な探索を行う。
: 追加・削除が高速に行えるデータの集まりからの高速な探索を行う。
: 同一ハッシュ値のデータを線形リストでつなぐ手法。
: 衝突時に再ハッシュを行う手法。
アルゴリズムの選択
次の文章の空欄に入る最も適切なものを選択しなさい。
データの集合から「探索さえ行えればよい」のであれば,探索に要する計算時間が アルゴリズムを選択すればよい。しかし,データの追加を頻繁に行うような場合は,たとえ探索が速くても,追加のコストが高くつく(時間がかかる,大量にメモリを使用する,実装が面倒など)ようなアルゴリズム である。
ある目的に対して,複数のアルゴリズムが存在する場合には,用途や目的,実行速度,対象となるデータ構造などを考慮してアルゴリズムを選択する。
番兵法
次の文章の空欄に入る最も適切なものを選択しなさい。
目的とするキー値(探したい値)をもつ要素に出会うまで,先頭から順に要素を する(なぞる)ことで,探索を実現するアルゴリズムを という。
なお、キー値と同じ値の要素を配列中で発見すると、 が終了する。
線形探索の平均探索回数
次の文章の空欄に入る最も適切なものを選択しなさい。
データ数をnとする。
線形探索においては、平均探索回数は となる。
※キー値が先頭にあれば1回で見つかるし、キー値が末尾にあればn回 (存在しなければn+1回) 探索しないといけないので、平均するとこのようになる。
ループと無限ループ
次の文章の空欄に入る最も適切なものを選択しなさい。
(a) while文やfor文によるループは、break(またはreturn) で強制的に抜け出すことができる。
(b) また、無限ループは次のようにして実現することができる。
下の図の空欄【ア】と【イ】に入るものを選択しなさい。
while (【ア】) {
/*中略*/
}
for (【イ】) {
/*中略*/
}【ア】
【イ】
(c) while(条件)の条件、反復条件である(つまり、条件が成立している間、ループ内の処理が繰り返される)。
※例えば、「while (i≤N) {処理」とすると、i≤Nが成り立っている間は、ずっとループ内の「処理」が繰り返し実行される。
関係演算子(==, <, >など)は、条件式が成立するとき(真のとき) を、成立しないとき (偽のとき) を生成する。
従って, while( )とすることにより、while (条件)の条件が、常に成立しているとみなされ、無限ループが実現できる。
探索関数の理解
次の文章の空欄に入る最も適切なものを選択しなさい。
【重要】
if文, for文, while文などは {} 内の処理が1つしかないとき、 {} を省略することができます。
※この例や教科書では上のように省略していますが、このような場合でも、(バグのもとなので) できるだけ省略しないようにしています。
下記の関数を見てみましょう。
int search(const int a[], int n, int key)
{
int i = 0;
while (【ア】) {
// (a)
if (i == n)
return -1; /*探索失敗*/
// (b)
if (a[i] == key)
return i; /* 探索成功 */
i++;
}
}(1) 上の【ア】には、 が入っており、 無限 を表現している。
(2) 【a】の箇所のif文の条件が成立するとき(つまりiの値がnのとき), iは をあらわしている。0は配列の先頭の要素番号
(3) 【a】と【b】より、search関数は、探索が失敗したとき-1を返し、探索が成功したとき、 をかえす。iはその配列の要素番号
(4) a[3]とa[6]に5が格納されているとする(その他の配列の要素には5以外の数字が格納されている)。このとき、5をキー値とした際、search関数は を返す。
番兵法の比較
次の文章の空欄に入る最も適切なものを選択しなさい。
(1) p.92 List3-1
int search(const int a[], int n, int key)
{
int i = 0;
while (【ア】) {
(a) if (i == n)
return -1; /*探索失敗*/
(b) if (a[i] == key)
return i; /*探索成功*/
i++;
}
}(2) p.95 List3-3
int search(int a[], int n, int key)
{
int i = 0;
a[n] = key; /*番兵を追加*/
while (【ア】) {
(c) if (a[i] == key)
break; /* 見つけた */
i++;
}
return i == n ? -1 : i; [d]
}<1> 上の図の(1)と(2)を比較すると、ループ内の判断(if文の箇所)が、(1)では 回、(2)では 回になっている。
データ数が多くなるほど、(2)の方法(番兵法)の方が有利になる。
<2> (2)の番兵法では、 を番兵として配列の に追加する。このため、配列の要素にキー値が存在するかどうかにかかわらず、 (【c】の箇所で) 必ずキー値が発見されることになる。
なお番兵法では、配列のサイズをデータ数よりも つ多めに確保する必要がある。
<3> ただし、発見したものが、もともとの配列内に存在しているものなのか、番兵であるのかを判断しなければならない (【d】の箇所)。
【d】の箇所の意味を考えてみる、この【d】の箇所では、iの値がnと等しいとき を返し、その他の場合には を返す。つまり、【c】のループを抜けた際のiの値が と等しいとき、「番兵を見つけた(探索失敗)」と判断されることになる。
構造体とポインタ
次のような実行結果が得られるように、プログラム中の空欄に入るものを選択しなさい。
英語 = 93
数学 = 86
#include <stdio.h>
struct _score {
int kokugo;
int eigo;
int math;
} score;
int main(void) {
score st = {85, 93, 86};
score *p;
printf("国語 = %d\n", pkokugo);
printf("英語 = %d\n", peigo);
printf("数学 = %d\n", pmath);
return 0;
}ハッシュ法(計算)
13個の要素を持つ配列 a (a[0]~a[12])、サイズ13のハッシュテーブルがあるとする。
例として、「14」をこの配列(ハッシュテーブル)に格納することを考える。ハッシュテーブルのサイズが13なので、14を13で割った余りである1の箇所、つまり、a[1]に14が格納されることになる。この余りの1をハッシュ値と呼ぶ。
※テーブルのサイズが13のとき、整数を13で割った余りは0~12になるため、すべてa[0]からa[12]に対応する。なお、このサイズには素数を用いることが多い。
このとき、下の文章の空欄に入る数値を入力しなさい。
(a) いま、「16」をハッシュテーブルに格納したい。16を13で割った余りは であるので、a[ ]に16が格納される。
(b) つぎに、「29」を格納したい。29を13で割った余りも3である。しかし、すでにa[3]には16が格納されている。このように が重複してしまう現象を と呼ぶ。
2. ハッシュテーブルのサイズが7 (a[0]~a[6]) であるときは、格納したいデータを で割った余りを求めることになる。
ハッシュ法(理論)
下の空欄に入る最も適切なものを選択しなさい。
・キー値とハッシュ値の対応関係が1対1である保証はなく、通常は 対1である。
・格納すべきバケットが重複(ちょうふくと読む)する現象は、 と呼ばれる。
・ が全くないと仮定する。このとき、探索・追加・削除に要する時間計算量はO( ) (一発でできるということ)である。
・ハッシュ表を大きくすれば の発生を抑えられるが、この一方で、記憶領域を ことになる。
・できるだけハッシュ値が偏らないように、ハッシュ表の容量は、 が好ましいとされている。
・キー値が整数でない場合、例えば、キー値が実数の場合には をする、文字列の場合には各文字に対する をするなどの方法がある。
チェイン法
チェイン法と同じ方法で、データを追加する場合を考える。
ここで、次のようにしてデータを追加する。
- ハッシュ表の容量(ハッシュテーブルのサイズ)を13とし、
- データを1, 2, 3, 13, 14, 15, 16の順に追加する。
このとき、下の図の空欄に入る数値を選択しなさい。
0 1 2 3 12 +-----+-----+-----+-----+ ... +-----+ | [ア]| [イ]| 15 | [エ]| | | +--|--+--|--+--|--+--|--+ ... +-----+ | | | | v v v v +-----+-----+-----+-----+ | [オ]| 2 | [キ]| | +-----+-----+-----+-----+
[ア]
[イ]
[エ]
[オ]
[キ]
スタック(Push/Pop)
スタックに関するプログラムについて、下の問いに答えなさい。
/*----- スタックを実現する構造体 -----*/
typedef struct {
int max; /* スタックの容量 */
int ptr; /* スタックポインタ */
int *stk; /* スタック本体(の先頭要素へのポインタ) */
} IntStack;
/*----- スタックにデータをプッシュ -----*/
int Push(IntStack *s, int x)
{
if (s->ptr >= s->max) /* スタックは満杯 */
return -1;
s->stk[s->ptr++] = x; /* [ア] */
return 0;
}
/*----- スタックからデータをポップ -----*/
int Pop(IntStack *s, int *x)
{
if (s->ptr <= 0) /* スタックは空 */
return -1;
*x = s->stk[--s->ptr]; /* [イ] */
return 0;
}(a) プログラム中の [ア] の箇所の処理内容は次のとおりである。すなわち、 を1つ増加 、xの値をPushする。
(b) プログラム中の [イ] の箇所の処理内容は次のとおりである。つまり、 を1つ減少 、データをPopする。
スタックの操作
上記のPop, Push関数を呼び出す、関数fとgに関する次のプログラムについて、下の問いに答えなさい。
なお、s1とs2は、それぞれ、スタック1と2を表しており、関数fとgの仕様は次の通りである。
- 関数fはスタック1からポップしたデータをそのままスタック2にプッシュする。
- 関数gはスタック2からポップしたデータを出力する。
void f(IntStack *s1, IntStack *s2)
{
int x;
Pop( [ア], [イ] );
Push( [ウ], [エ] );
}
int g(IntStack *s2)
{
int x;
Pop( [オ], [カ] );
return x;
}プログラム中の空欄に入るものを選択しなさい。
[ア]
[イ]
[ウ]
[エ]
[オ]
[カ]
データ構造の選択
FIFOの処理に適したデータ構造はどれか
キューの操作
待ち行列に対する操作を次の通り定義する
- ENQ n : 待ち行列にデータnを挿入する
- DEQ : 待ち行列からデータを取り出す
空の待ち行列に対し、
ENQ1, ENQ2, ENQ3, DEQ, ENQ4, ENQ5, DEQ, ENQ6, DEQ, DEQ
の操作を行った
次にDEQ操作を行った時、取り出される値はどれか
キューの記述
キューに関する記述として、最も適切なものはどれか
番兵法の実装
次の文章の空欄に入る最も適切なものを選択しなさい。
(1) p.92 List3-1
int search(const int a[], int n, int key)
{
int i = 0;
while ( ) {
(a) if ( )
return ; /*探索失敗*/
(b) if ( )
return ; /* 探索成功 */
i++;
}
}(2) p.95 List3-3
int search(int a[], int n, int key)
{
int i = 0;
a[n] = key; /* 番兵を追加 */
while ( ) {
[c] if ( )
break; /* 見つけた */
i++;
}
return ; [d]
}<1> 上の図の(1)と(2)を比較すると、ループ内の判断(if文の箇所)が、(1)では 回、(2)では 回になっている。
データ数が多くなるほど、(2)の方法(番兵法)の方が有利になる。
<2> (2)の番兵法では、 を番兵として配列の に追加する。このため、配列の要素にキー値が存在するかどうかにかかわらず、([c]の箇所で)必ずキー値が発見されることになる。
なお番兵法では、配列のサイズをデータ数よりも つ多めに確保する必要がある。
<3> ただし、発見したものが、もともとの配列内に存在しているものなのか、番兵であるのかを判断しなければならない([d]の箇所)。
[d]の箇所の意味を考えてみる。この[d]の箇所では、iの値がnと等しいとき を返し、その他の場合には を返す。つまり、[c]のループを抜けた際のiの値が と等しいとき、「番兵を見つけた(探索失敗)」と判断されることになる。